

 极品老太之颞下颌是真正的朋友
@[email protected]
极品老太之颞下颌是真正的朋友
@[email protected]
- 推理&恐怖&科幻爱好者
- (包括垃圾推理)(但永远恨清凉院流水)
- 大龄混乱中立人
- 麻烦看下置顶以免莫名冲突
- 用刻板印象来概括就是
- 5W4 intp
- 忠于梦幻
- 以有涯随无涯
梦饮酒者,旦而哭泣,总有些真笑,也有真痛
Joined Jun 2022

以前租房子的时候,房东养的大肥猫经常喜欢站在我身上,然后把屁眼对着我。我很尴尬,只能敷衍客气地夸一声“好菊”,然后把她赶走。
说起来她确实是个热情优雅的大肥猫,我第一天入住时,她把自己的玩具叼到我脚边邀请我共赏,有时候我在沙发上睡着了,醒来会发现她也睡在我怀里。
房东说她之前被遗弃过,所以特别粘人。
我搬走的那天,她在门后惊恐地看着我,喵喵叫,开门出来,喵喵叫,飞快地跟着我走了几步,喵喵叫,回房间看到房东,喵喵叫。
我以为她给我类似长亭外古道边的送别,结果房东蹲下来抱着她说:黛珂西,客人是要搬走了,不是被遗弃了。。。。
刷到首页聊嫉妒情绪,虽然会用这个词但在记忆里我近20年好像都没有过真正的嫉妒……个人理解里的真嫉妒约等于“你有什么行的这本该是我的”。我有点像那种单细胞生物,看到别人有我想要的东西我只会:握草!牛逼!握草!我也想要!我想要我想要我想要我想要得快发疯了!
最难受的部分也就是太想要却得不到。但上述心态无论再怎么疯狂都跟我理解的真正嫉妒不是一回事,因为我根本不认为对方有的那个东西跟我想要的东西是同一个且我们互相影响,举例来说的话,对方有一个苹果跟我能不能得到苹果毫无关系,我想要的并不是the苹果,而是a苹果,对方有的是苹果A,而我仅仅是想要一样好吃的苹果B,所以我根本不必花费力气向对方付出任何感情,我只会对那个苹果付出感情…这个关系里面,对方仅仅是向我展示苹果的工具人,我再次确信了好喜欢好想要苹果,甚至不会仔细看对方。
还有一种情况就是目前确实只有一个苹果,而且我俩争抢的就是那一个苹果,逻辑就回到了是否认可“本该是我的”,这里有两种分支:或者我俩的差别显而易见以至于苹果若真给了我那才见鬼,这种情况下不可能产生嫉妒因为我也认可分配结果,没有”本该“。又或者我俩势均力敌各有长短和机缘,最终阴差阳错混沌系统下苹果到了对方手里,这种情况下我可能会遗憾后悔失望羡慕,但仍然不觉得有”本该“,因为我会把一切这边错了但对方竟然对了的都算成”你有什么行的“这块,换而言之,混沌系统里的对尤其恐怖,因为不可预测不可控制。当然,我应该会不断反刍当时怎样怎样会不会好点,但同理,这个反刍里没有对面那个人的存在,只有我跟我的旅途。
各种开动物园养动物文,只要开了跟动物说话的金手指且沟通得有来有回主谓宾清晰词汇量丰富,那这篇文基本上就完了!
苍鹭 邀请您参加疯狂星期四观影会!
地点:B站一起看(需要B站大会员账号
会议主题:完美音调2 Pitch Perfect 2 (2015)
类型: 喜剧 / 音乐
片长: 115 分钟
时间:今天晚上七点半!(现在!
点击链接加入:https://m.bilibili.com/bangumi/theatre/invite?roomid=176769061&invitemid=514270&seasonid=42735&epid=740368&room_mode=0&token=0a5469df60edfdc0dfe1cfc7469f1d1a

每次 当我有某条嘟文获得了很多点赞/转发 我都会 从 并不是有很多人喜欢这条嘟文 而是 从 通知列表 欣赏大家多姿多彩的ID中 获得 很多的快乐
RT某套经典推理小说短篇合集的序言也这样啊啊啊,还特么好心地把所有诡计分门别类整理了,生怕泄底不够有效率!!
所以推理小说千万别看序言,至少遇到三四次了,真不知道啥时候会来这么一出!还有一次是一个作家给另一个作家写序言结果把诡计夸奖/泄底了一番!我只能善良地认为这个写序的作者不知道他这篇是放在最开始的……

避雷果麦经典出版的欧亨利短篇小说集之:这个傻屌编者在编者导读里把本书中所有小说剧情反转都剧透了 😅
天天惦记着侵犯自我的人实际上就是没有进入这条支线,支线真玩家其实是欢天喜地融化了消失了被瓜分了被侵蚀了又十年或一眨眼自我包含进了更多的东西……那也没有办法,对于两边的人来说这都是他们唯一的选择,有至福的人看不到其余景象

那啥,忘记说了,其实奶油可以直接用喷射奶油的,不需要打发而且非常快手,还有漂亮的花纹。
另补充一个技巧,如何让喷射奶油断得很自然:
在停止喷射之后把喷射头往刚刚挤出来的奶油里怼一下。
另外喷射奶油一坨坨挤在油纸上面,在冰箱冷冻层冻硬,就是美味的ice cream bite 了。
感觉最近考试季,应该也许很多人家里都有喷射奶油吧……毕竟这玩意可以直接往嘴里怼,相当方便……

大家好 有没有好玩的书推荐 没有别的标准只要你觉得好玩就行

感觉很多外向人没弄明白还喜欢社交霸凌我们内向人(特指我),是根本不懂,我们不是害怕或者害羞或者紧张社交行为或者“需要锻炼”,而是单纯不觉得每分每秒都搁那咋咋呼呼吵吵闹闹高谈阔论呼朋引伴上厕所手牵手make any sense……很难理解吗……

猫漂流里面水豚的声音原本是工作人员去动物园采集,然而水豚十分沉默,只能让动物园员工挠水豚痒痒促使其发声,可惜水豚音调太高,不符合电影需求,于是水豚的配音由骆驼担任(萌)

欧对了
腾讯不是出个腾讯元宝么
里面有一条是任何用户输入都会被tx拿走训练ai,而且你输入的文字的版权也归腾讯哦
你自己写了篇小说,放进腾讯元宝检查错别字,然后你的小说就归腾讯了
大家懂了嘛~ ![]()

看小红书帖子,问猫坐在床上屁眼会接触到床单吗,评论说我家有个玻璃茶几,猫坐在上边时我特地观察过👀,它会把菊花收合起来。这是我见过最让我想说那很有生活了的人
清晰边界消失与融合型真爱一瞬确实就是不“进步”的甚至不“健康”的,但是不这样就拿不到,这就好像你想要的套餐玩具必须到店购买才给,不承认和不想体验完全是两回事,但话说回来,又能有什么办法,不这样就拿不到的东西多了去了……


↓2011 年,英国有一项调查发现,30% 的男性会故意把家务搞砸,以免将来又被要求做同样的家务。他们认为,伴侣在失望之余,会觉得自己做比收拾伴侣马虎完成的残局来得简单。他们料想得没错,多达 25% 的受访男性表示,他们不再被要求帮忙做家务,64% 表示他们只偶尔被要求帮忙[1]。另一项调查有同样的结果,调查显示女性平均每周要花整整三个小时,重做她们交派给伴侣的家务,2/3 的受访女性认为伴侣已经尽力了[2]。
………………啊啊啊啊啊啊
燕云16
田英不错,但这样的话他装逼的风格就跟月神感情线在我心里不太兼容了,月神那种真味儿跟田英的微妙假味儿凑不到一起去

{kind=link}
{kind=link}
{kind=link}
{kind=link}
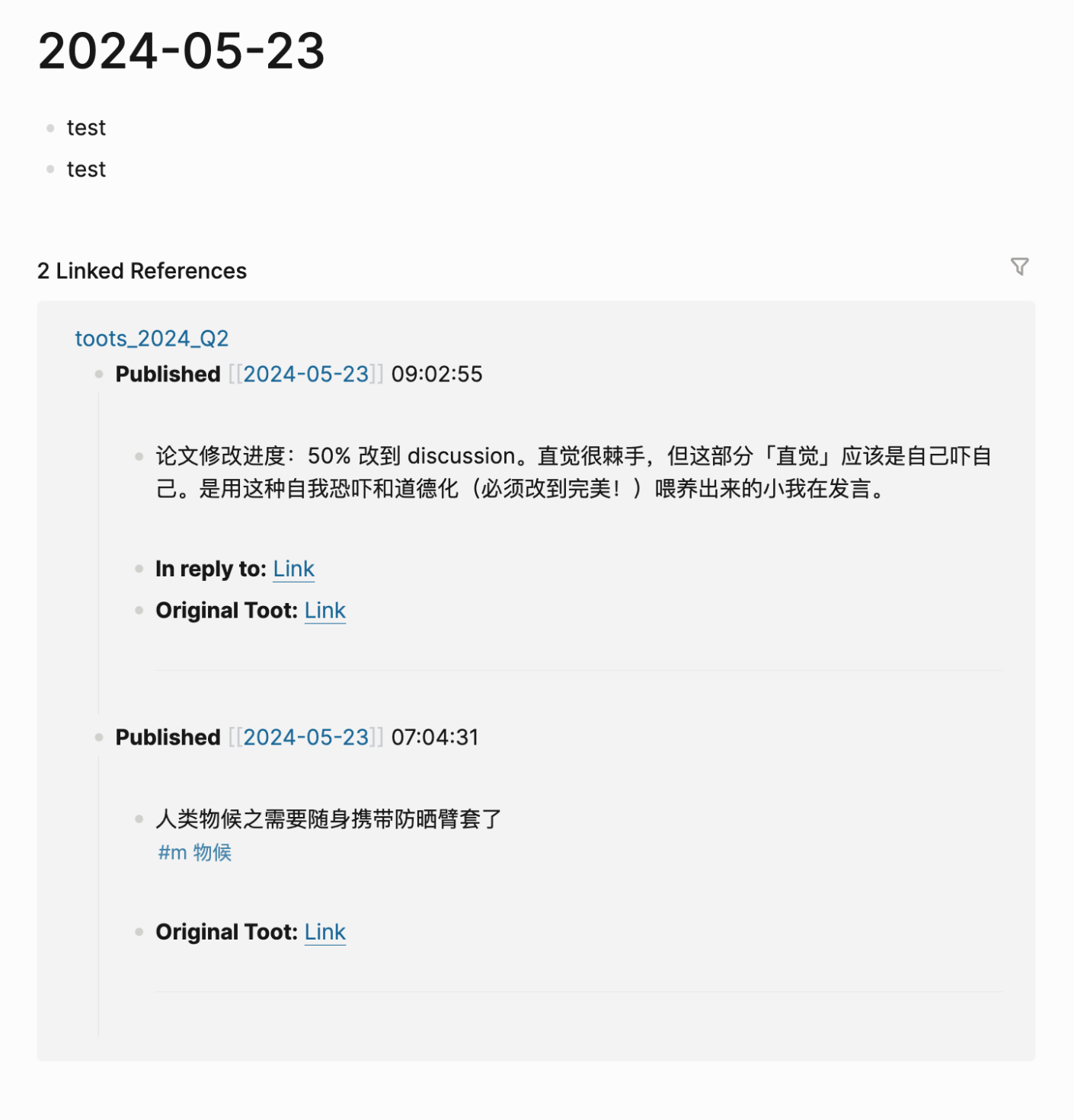
很需要有个途径可以回溯和感受自己的旧嘟文,感受想法的变化和发展。导出了一下毛象存档,和 GPT 调试了几轮完成了一个 python 脚本,实现了:
1. 对毛象存档中的嘟文 json 文件进行抓取,仅保留时间、嘟文、回复链接和原始嘟文链接
2. 对所有处理结果嘟文,每个季度导出一个 .md 文件,不然会文件过大。导出后大概是 100-600 k 一个文件不等,任何 markdown 软件都可以轻松编辑。
3. 处理抓取文件的格式,使其符合 logseq 里自己想要的格式(加 bullet 符号、加空行、bullet 之间有从属关系、分隔符)
4. 给日期信息加双方括号,这样在日志页面就可以用 linked references 的形式,看到这一天自己发的嘟嘟
5. 对 tag 进行单独处理,tag 后加空格
6. 默认对「回复他人的嘟嘟」且「小于 150 字符」的内容,进行自动折叠(超重要
在 Logseq 中的效果如图,目前效果基本满足需求 ![]()
把脚本传到 wormhole 了,想试试的友友可以自取。把脚本放在嘟文 json 文件所在的文件夹里运行即可。
https://www.dropbox.com/scl/fi/o7flj56ybb20w6xjreq8r/extract_to_md.py?rlkey=zw41vx4y8v51d3sedv9xgwpuq&e=1&dl=0
#m工具
update:
修复了上方失效的链接。
此外提供一个在此基础上修改的版本:
- 对于自己回复他人的嘟文,小于等于 150 字符的,直接删除(可能主要是表情包哈哈哈之类的闲聊内容)
- 对于自己回复他人的嘟文,大于 150 字符的,在 Logseq 中显示为折叠。整体内容会更清爽
https://www.dropbox.com/scl/fi/x7e43cmwuvs36oist7b9r/extract_to_md_delete150.py?rlkey=015ew77494yzegshybcgksbc2&st=ney2ip0b&dl=0
以及这次导入发现 logseq 软件的处理和同步好像快了很多,一万多条日的一下就关联好了
对于不熟悉 python 脚本怎么用的朋友:只需要把脚本放在下载好的毛象数据中(和已解压的outbox.json 在同一个文件夹中),然后用终端运行就好,可以问问 GPT
{kind=link}
{kind=link}
- 推理&恐怖&科幻爱好者
- (包括垃圾推理)(但永远恨清凉院流水)
- 大龄混乱中立人
- 麻烦看下置顶以免莫名冲突
- 用刻板印象来概括就是
- 5W4 intp
- 忠于梦幻
- 以有涯随无涯
梦饮酒者,旦而哭泣,总有些真笑,也有真痛
Joined Jun 2022
